
تصور کنید سر جلسهی آزمون نشستهاید. سوالی را میبینید که هیچ ایدهای دربارهی پاسخ آن ندارید. زمان در حال گذر است، استرس بالا میرود و ناگهان این سوال در ذهنتان جرقه میزند: چگونه شانسی تست بزنیم؟ شاید فکر کنید شانسی زدن تست تنها یک قمار بیفایده است، اما اگر کمی هوشمندانه عمل کنید، ممکن است این روش ناجی شما شود!
آیا تست زنی شانسی اما صحیح واقعا امکانپذیر است؟ یا شانس چیزی است که نمیتوان به آن اعتماد کرد؟ این سوال مخصوصاً در آزمونهای چالشی مانند المپیاد زیست اهمیت پیدا میکند، جایی که حتی یک پاسخ درست یا غلط میتواند سرنوشت شما را تغییر دهد. در این مقاله، روش تست زدن شانسی را بررسی میکنیم و یاد میگیریم که چگونه حتی در شرایط نامطلوب، احتمال موفقیت را افزایش دهیم. آمادهاید این راز را کشف کنیم؟ پس بیایید شروع کنیم!
در این نوشتـه قصد داریم صحت تعدادی از دیدگاه های رایج در مورد شانسی زدن گزاره ها در مرحله 2 را براساس داده های واقعی بررسی کنیم. به عنوان مثال یکی از این دیدگاه ها این است که: «اگر جواب 4 گزاره را با اطمینان تعیین کرده باشیم، میتوانیم جواب گزاره پنجم را براساس تعداد گزاره های غلط از 4 تای قبلی حدس بزنیم!»
روش کار
تعدادی از اعضای گروه تلگرامی المپیادلب داوطلب شدند و جواب های تمامی سوالات ص/غ دوره های 18 تا 22 را مطابق با پاسخنامه رسمی این آزمون ها جمع آوری کردند. در تمامی نمودار هایی که در ادامه آمـدهاند، 0 نشان دهنده گزاره غ و 1 نشان دهنده گزاره ص است. دقت کنید این آنالیزها فقط شرایطی را بررسی میکنند که از جواب 4 گزاره اطمینان دارید و 1 گزاره را شک دارید (مثلا گزاره های 1 و 2 و 4 و 5 را جواب دادید و در گزاره 3 شک دارید).
دقت کنید که برای هر سوال تمامی پنج حالت اینکه کدام گزاره مشکوک باشد در نظر گرفتـه شـده است. همچنین، در نمودارها منظور از کلمه statement، گزاره های سوالات است.
بخش اول – بررسی فراوانی سوالات مختلف بر اساس تعداد گزاره های غلط آن ها
در نمودار زیر، فراوانی تمامی سوالات دوره های 18 تا 22 از نظر تعداد گزاره های آن ها نشان داده شـده است.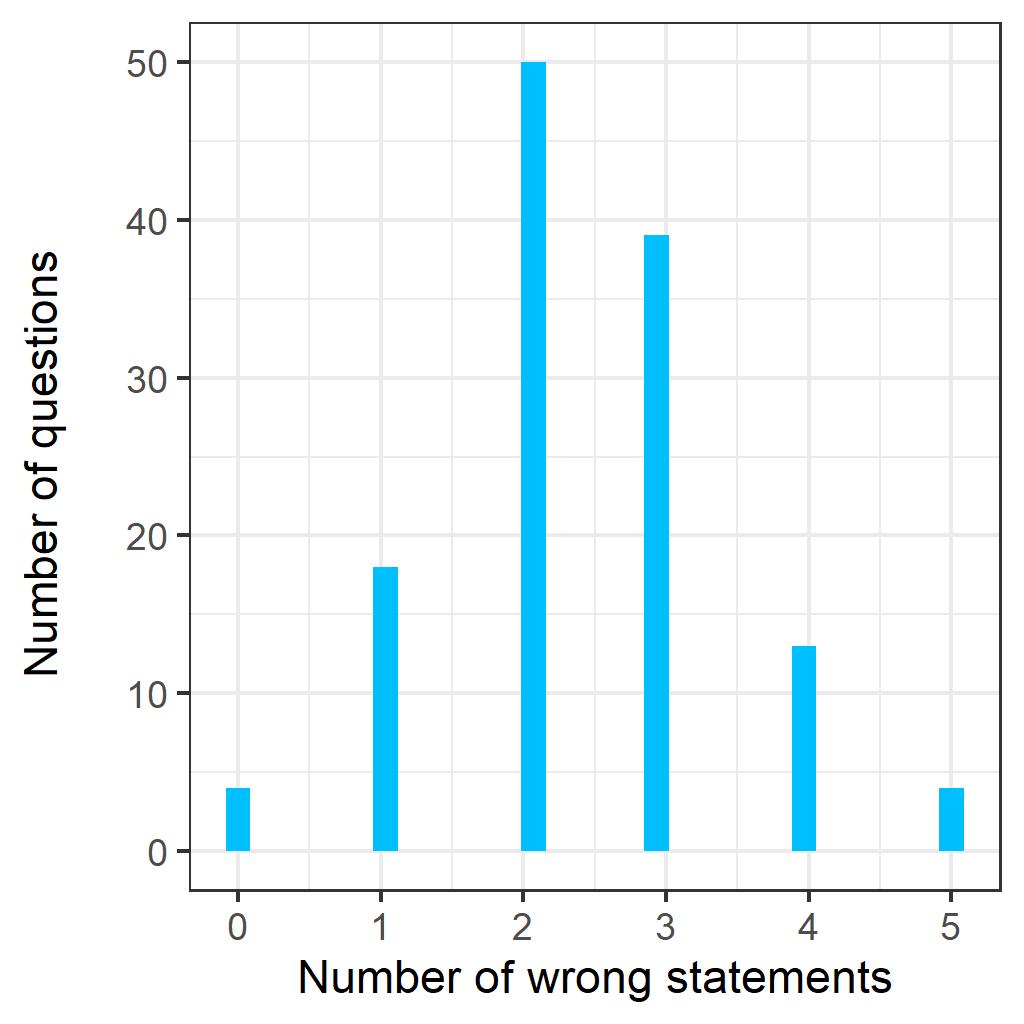

همانطور که مشاهده میکنید، سوالاتی که 2 یا 3 گزاره غلط دارند به مراتب از سایر سوالات فراوان تر بوده و 70 درصد سوالات را تشکیل میدهند.
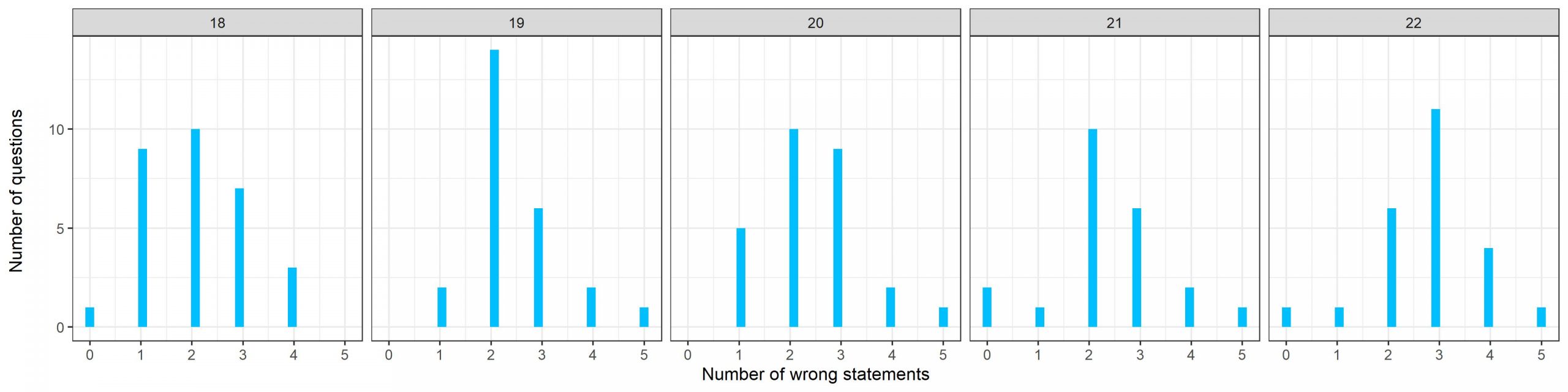
میتوان این نمودار ها را به تفکیک دوره نیز بررسی کرد:

بخش دوم – بررسی احتمال غلط بودن گزاره بر اساس شماره گزاره مشکوک
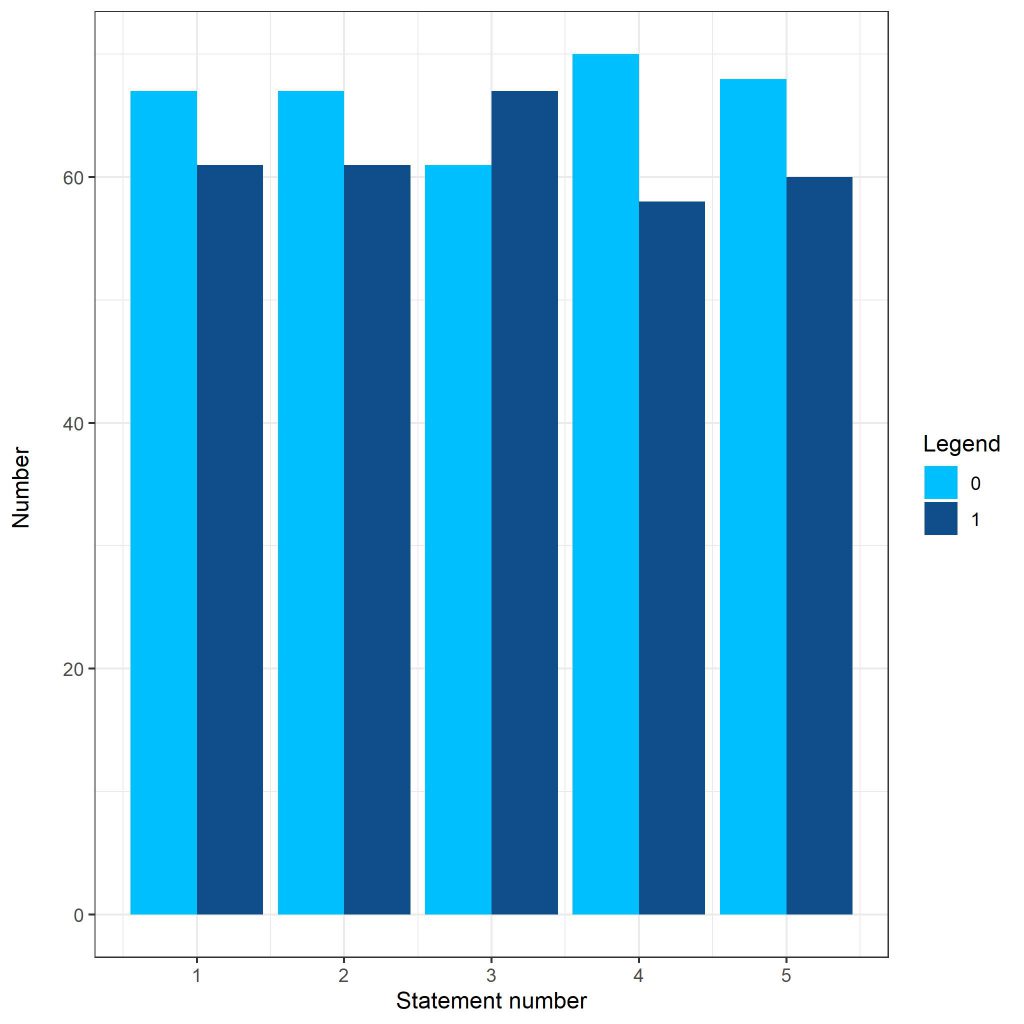
در نمودار زیر تعداد گزاره های ص و غ براساس شماره گزاره را در کل سوالات میتوانید ببینید.
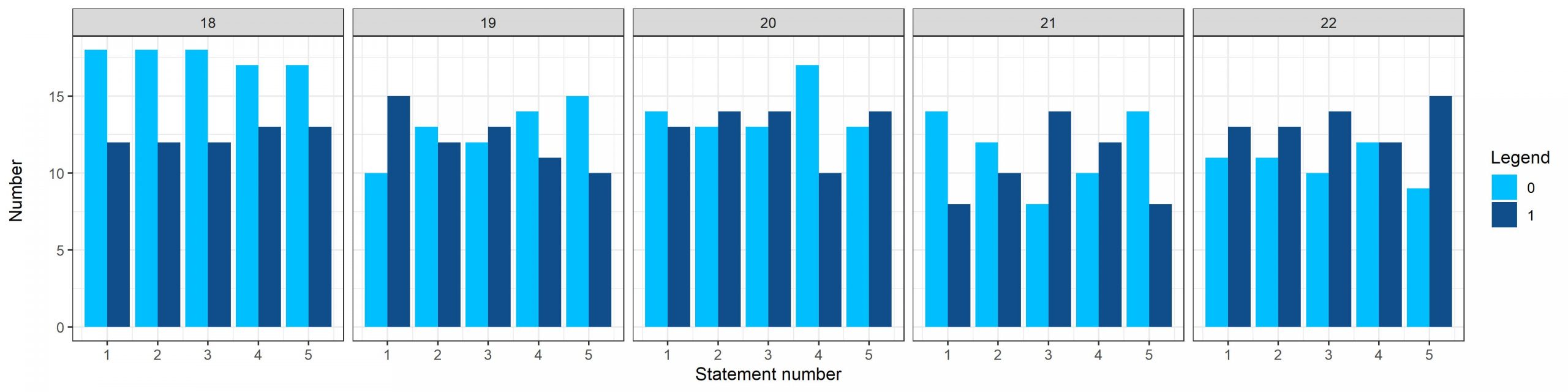
با این اوصاف، شاید بد نباشد ببینیم که آیا این افزایش احتمال غ بودن به سمت گزاره های آخر، در تمامی دوره ها صادق بوده است یا خیر.

بخش سوم – بررسی احتمال غلط بودن گزاره پنجم بر اساس تعداد گزاره های غلط قبلی
در نمودار پایین، محور x نشان دهنده ی این است که از بین 4 گزاره ای که از جواب آن ها مطمئنید، چه تعدادی غ بوده اند. محور y هم نشان دهنده تعداد کل گزاره هایی است که با این شرایط جوابشان ص یا غ بوده است.
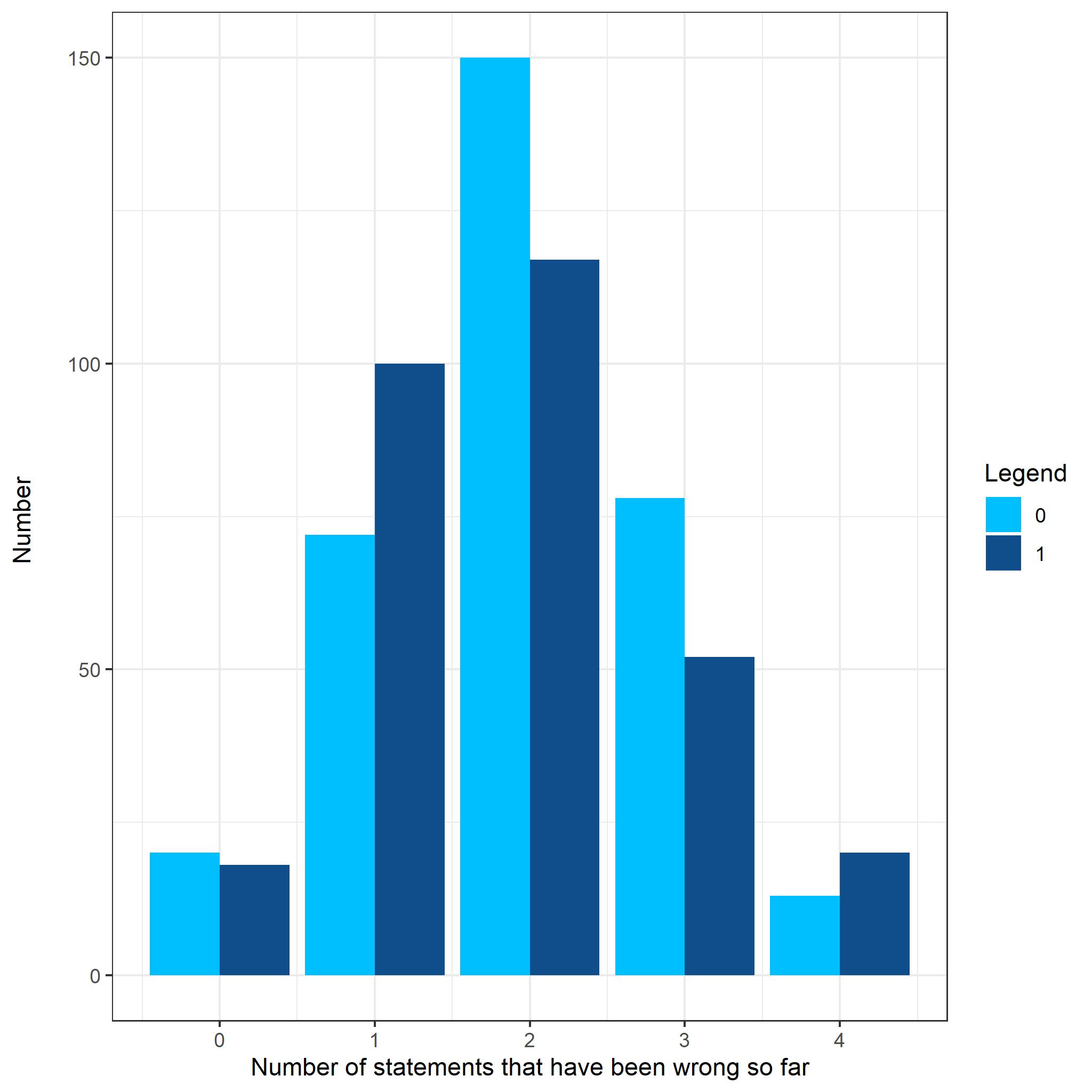
بر اساس این نمودار به نظر میآید که در هنگام روبرو شـدن با گزاره مشکوک، اگر 2 یا 3 عدد از گزاره های قبلی غ بودند، احتمال غ بودن گزاره مشکوک کمی بیش از 50 درصد است.
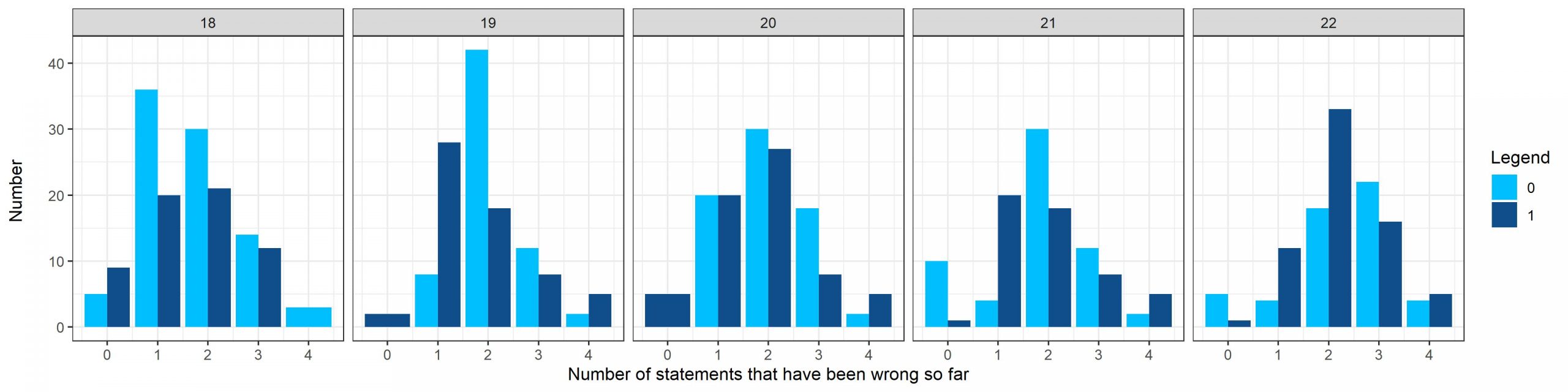
حال اگر همین بررسی را به تفکیک دوره ها انجام دهیم نمودار زیر حاصل میشود:
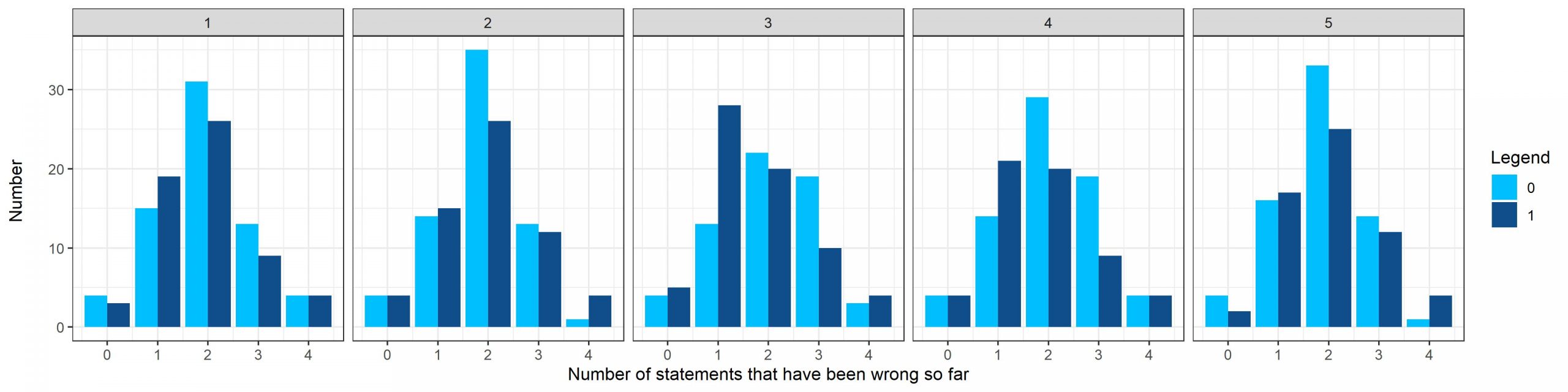
ممکن است فکر کنیم که علاوه بر تعداد گزاره هایی که تا کنون غ بوده اند، شماره گزاره مشکوک هم مهم است. مثلا اگر گزاره شماره 5 را شک داشتـه باشیم، آیا احتمال ص بودن آن بیشتر است؟ نمودارهای زیر مشابه نمودار های قبلی بوده اما براساس شماره گزاره مشکوک تفکیک شـده اند.
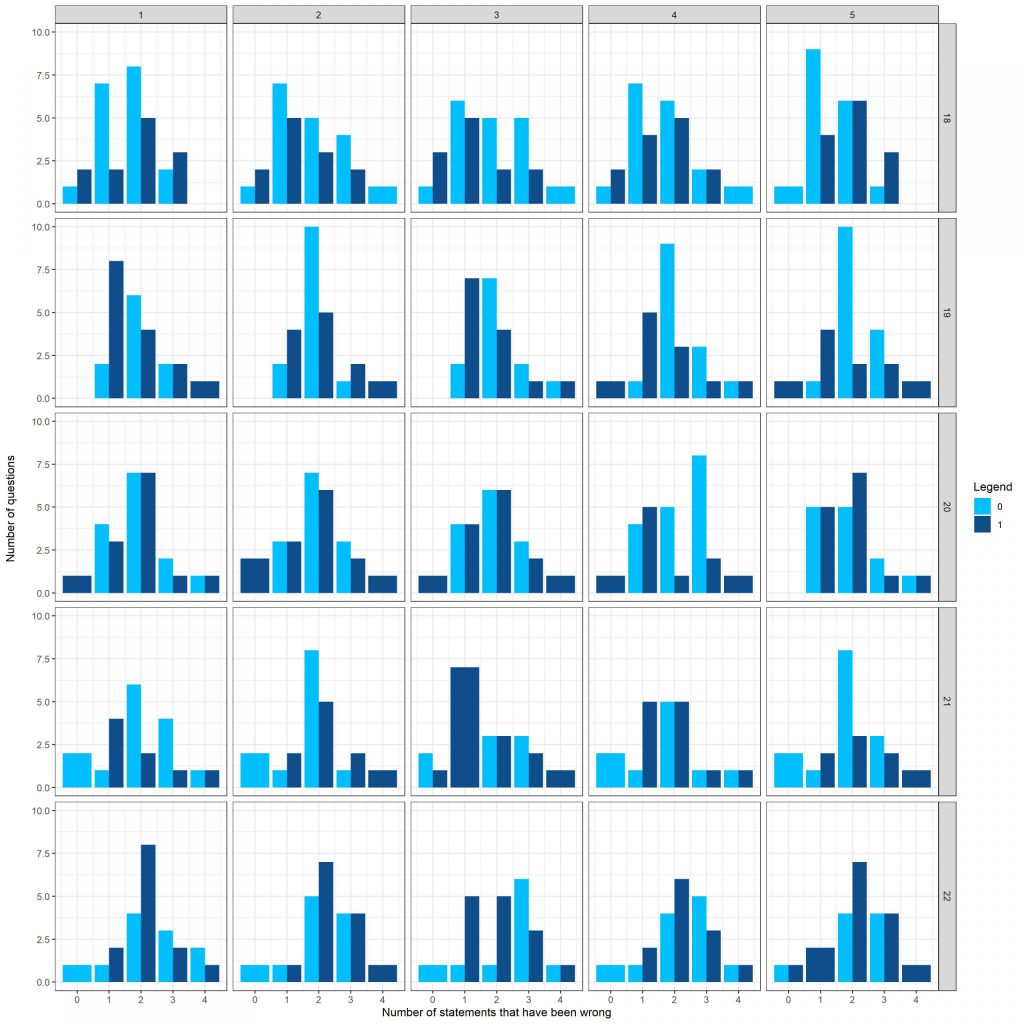
حال میپرسید: «خب نمیشود همزمان هم دوره را لحاظ کرد هم شماره گزاره را؟ چرا میشود. اما نمیشود آن را تحلیل کرد :). این بخش را میگذارم بر عهده شما:

بخش چهارم – بهره گیری از هوش مصنوعی برای پیش بینی ص یا غ بودن گزاره!
بله ما که نتوانستیم، ببینیم کامپیوتر چه میکند! در اینجا از ۳ الگوریتم مناسب برای این مشکل (یک دستهبندی دودویی) استفاده میکنیم: Logistic Regression، Support Vector Machines (SVM) و Naive Bayes. در ابتدا نتایج مربوط به Logistic regression به عنوان ساده ترین روش را مشاهده کنیم. این مدل سعی میکند بر اساس شماره دوره، شماره گزاره، و تعداد گزاره هایی که تا کنون غلط بوده اند، ص یا غ بودن گزاره را پیش بینی کند.
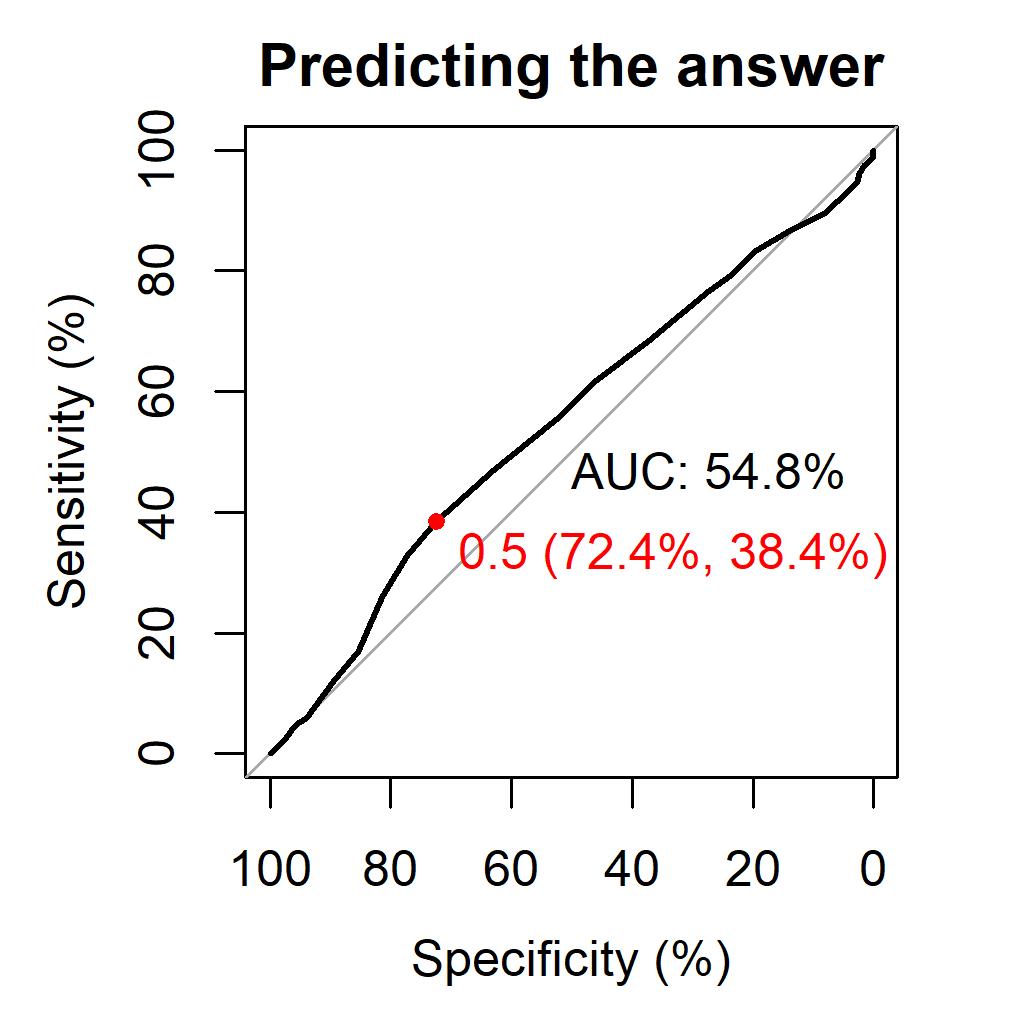
ممکن است با نمودار بالا که یک نمودار Receiver operating curve (ROC) است آشنا باشید. اگر نباشید هم با اصطلاحات sensitivity (حساسیت) و specificity (ویژگی) استفاده شـده در آن حتما آشنا هستید. در این نمودار، خط صاف وسط نشان دهنده حالتی است که شما به صورت کاملا شانسی تصمیم بگیرید. حال هر چقدر خط مربوط به مدل ما (خط تیره) از این خط صاف دورتر باشد، به معنی این است که مدل ما پیشبینی بهتری انجام میدهد (اصطلاح تخصصی آن این است که Area under the curve (AUC) بیشتری دارد). همانطور که مشاهده میکنید، مدل ما عملا تفاوتی با شانسی جواب دادن ندارد.
برای صرفهجویی در فضا و زمان، نمودارهای SVM و Naive Bayes را نشان نمیدهم. اما توجه کنید که دقت در هر دو مدل ۵۳٪ بوده است!
نتیجه گیری نهایی و عملی
1- بهصورت عملی، تعداد گزارههای غلط قبلی هیچ تأثیری بر احتمال غلط بودن گزاره بعدی ندارد. این احتمال همچنان ۵۰/۵۰ باقی میماند.
2- تنها تخمین ممکن این است که اگر پاسخ بیشتر سوالات را بدانید، میتوانید تعداد غلطها را در نظر گرفته و بر اساس نمودار بخش اول تحلیل کنید. مخصوصاً برای سوالاتی با ۰ یا ۵ گزاره غلط، زیرا این نوع سوالات بسیار کم هستند. تاکنون، در هیچ آزمونی بیش از ۳ سوال از این نوع وجود نداشته است.
3- خب! حال که فهمیدیم احتمال پیشبینی ص/غ برابر ۵۰/۵۰ است، باید به این سوال پاسخ دهیم که آیا با این احتمال باید جواب بدهیم یا نه. این موضوع در یک نوشتهی بعدی بررسی خواهد شد.
جمع بندی
تست شانسی یکی از روشهایی است که بسیاری از داوطلبان در آزمونهای چندگزینهای به آن متوسل میشوند. همانطور که بررسی کردیم، احتمال پیشبینی صحیح یک گزینه ۵۰/۵۰ است، اما این احتمال بهتنهایی نمیتواند موفقیت را تضمین کند. روشهای هوشمندانه مانند حذف گزینههای نادرست، استفاده از الگوهای رایج و انتخاب گزینههای ثابت میتوانند شانس موفقیت را افزایش دهند. در مقابل، در آزمونهایی با نمره منفی، تست زدن شانسی میتواند بیشتر از آنکه مفید باشد، به ضرر داوطلب تمام شود.
همانطور که آلبرت اینشتین (Albert Einstein) میگوید: «دیوانگی یعنی انجام دوبارهی یک کار و انتظار نتیجهی متفاوت داشتن.» اگر همیشه بدون منطق گزینهای را شانسی انتخاب کنیم، نباید انتظار نتیجهای متفاوت و موفقیتآمیز داشته باشیم.
المپیاد لب
سوالات متداول
1 – چگونه شانسی تست بزنیم که احتمال موفقیت بالاتری داشته باشد؟
برای تست زنی شانسی اما صحیح، گزینههای نادرست را حذف کنید، الگوهای رایج در پاسخها را بشناسید و همیشه یک گزینهی ثابت را انتخاب کنید تا شانس موفقیتتان بیشتر شود.
2 – آیا تست شانسی در آزمونهایی با نمره منفی هم مؤثر است؟
شانسی زدن تست در آزمونهای نمره منفی میتواند ریسک بالایی داشته باشد. بهتر است فقط زمانی این روش را استفاده کنید که بتوانید گزینههای اشتباه را با منطق حذف کنید.
3 – روش تست زدن شانسی در سوالات سخت چیست؟
در سوالات سخت، تست زنی شانسی را با تحلیل کلمات کلیدی سوال انجام دهید، گزینههای اغراقآمیز را حذف کنید و یک گزینهی ثابت برای پاسخهای شانسی انتخاب کنید.